728x90
데이터: hotel.csv
1. hotel 데이터셋


- hotel: 호텔 종류
- is_canceled: 취소 여부
- lead_time: 예약 시점으로부터 체크인 될 때까지의 기간(얼마나 미리 예약했는지)
- arrival_date_year: 예약 연도
- arrival_date_month: 예약 월
- arrival_date_week_number: 예약 주
- arrival_date_day_of_month: 예약 일
- stays_in_weekend_nights: 주말을 끼고 얼마나 묶었는지
- stays_in_week_nights: 평일을 끼고 얼마나 묶었는지
- adults: 성인 인원수
- children: 어린이 인원수
- babies: 아기 인원수
- meal: 식사 형태
- country: 지역
- distribution_channel: 어떤 방식으로 예약했는지
- is_repeated_guest: 예약한적이 있는 고객인지
- previous_cancellations: 몇번 예약을 취소했었는지
- previous_bookings_not_canceled: 예약을 취소하지 않고 정상 숙박한 횟수
- reserved_room_type: 희망한 룸타입
- assigned_room_type: 실제 배정된 룸타입
- booking_changes: 예약 후 서비스가 몇번 변경되었는지
- deposit_type: 요금 납부 방식
- days_in_waiting_list: 예약을 위해 기다린 날짜
- customer_type: 고객 타입
- adr: 특정일에 높아지거나 낮아지는 가격
- required_car_parking_spaces: 주차공간을 요구했는지
- total_of_special_requests: 특별한 별도의 요청사항이 있는지
- reservation_status_date: 예약한 날짜
- name: 이름
- email: 이메일
- phone-number: 전화번호
- credit_card: 카드번호
📌필요없는 columns 제거

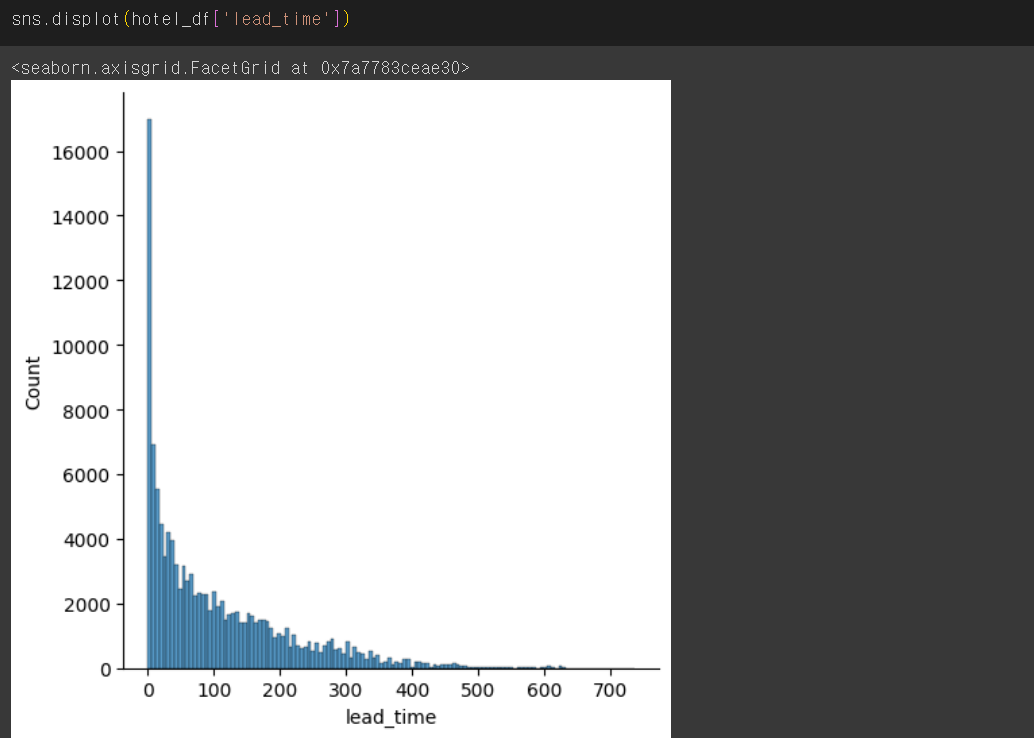





📌'calendar'모듈 이용하기


'order=months' 로 x좌표를 월 순서대로 정렬하기



✔️corr() : 열들 간의 상관계수를 계산한다.
- 상관계수의 범위: -1에서 1사이. 1: 완벽한 양의 상관관계, -1: 완벽한 음의 상관관계, 0: 상관관계 없음.
- 데이터프레임의 각 열에 대한 계산: 열들이 숫자형 데이터여야 함.
- NaN 값 처리: NaN 값이 포함된 열은 상관계수 계산에서 제외되거나 NaN으로 반환될 수 있다.



결측값 제거


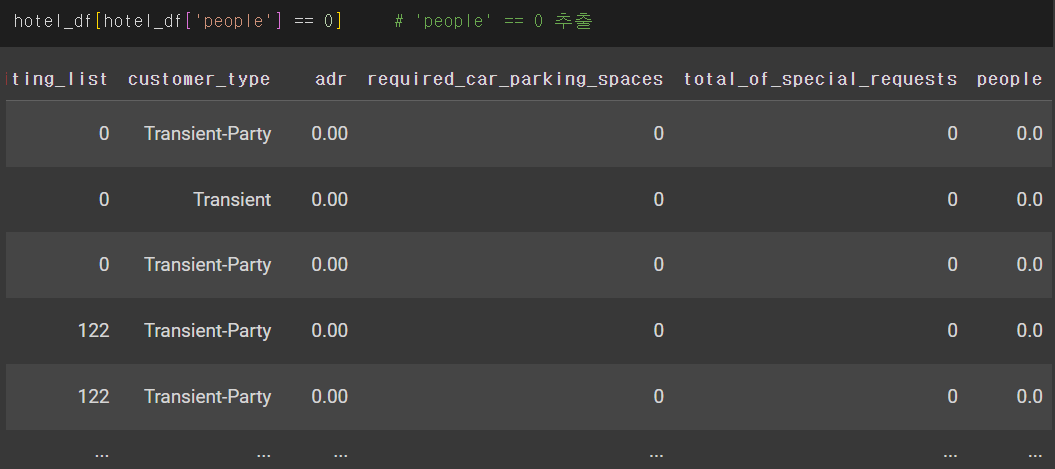









📌 'is_canceled' 예측하기

2. 앙상블(ensemble) 모델
- 여러개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법을 사용하는 모델
- 보팅(Voting)

- 배깅(Bagging)

- 부스팅(Boosting)

- 스태킹(Stacking)

3. 랜덤 포레스트(Random Forest)
- 머신러닝에서 많이 사용되는 앙상블 기법 중 하나이며, 결정 나무를 기반으로 함
- 학습을 통해 구성해 놓은 결정 나무로부터 분류 결과를 취합해서 결론을 얻는 방식
- 랜덤 포레스트의 트리는 원본 데이터에서 무작위로 선택된 샘플을 기반으로 학습함
- 각 트리가 서로 다른 데이터셋으로 학습되어 다양한 트리가 생성되며 모델의 다양성이 증가함
- 분류와 회귀 문제에 모두 사용할 수 있으며, 특히 데이터가 많고 복잡한 경우에 매우 효과적인 모델
- 성능은 꽤 우수한 편이나 오버피팅 하는 경향이 있음
✔️ 'is_canceled' 에 대해 0과 1 두가지 클래스이므로 각 클래스에 속할 확률을 나타내는 배열을 반환한다.



4. 머신러닝/딥러닝에서 모델의 성능을 평가하는데 사용하는 측정값
- Accuracy: 올바른 예측의 비율
- Precision: 모델에서 수행한 총 긍정 예측 수에 대한 참 긍정 예측의 비율
- Recall: 실제 긍정 사례의 총 수에 대한 참 긍정 예측의 비율
- F1 Score: 정밀도와 재현율의 조화 평균이며, 정밀도와 재현율 간의 균형을 맞추기 위한 단일 메트릭으로 사용
- AUC-ROC Curve: 참양성률(TPR)과 가양성률(FPR)간의 균형을 측정



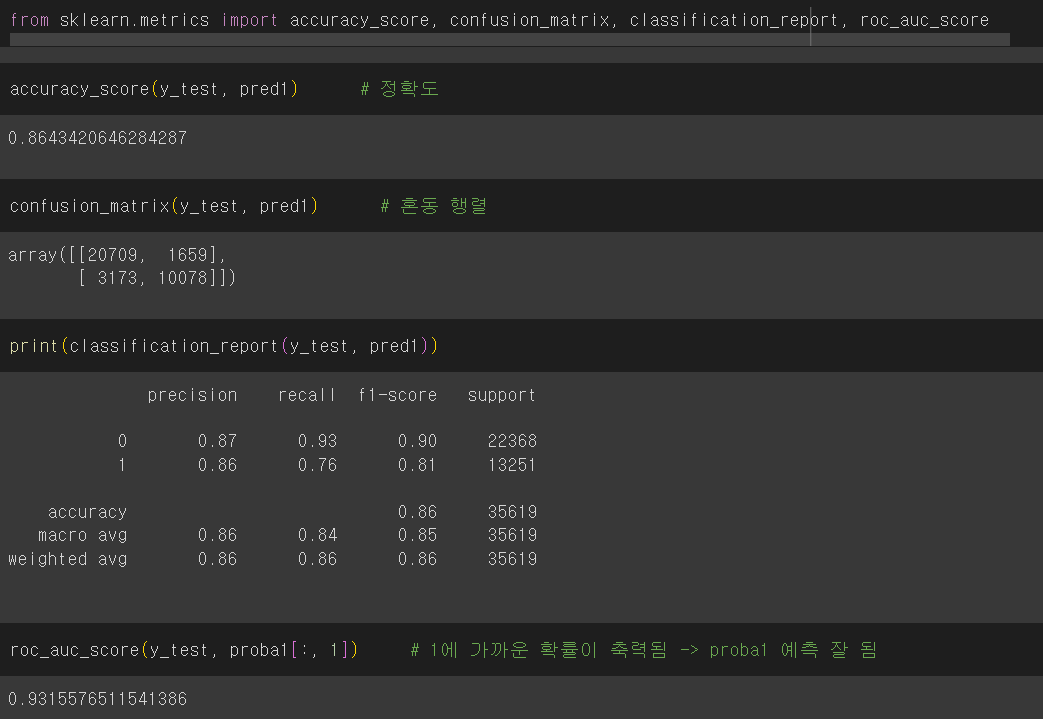

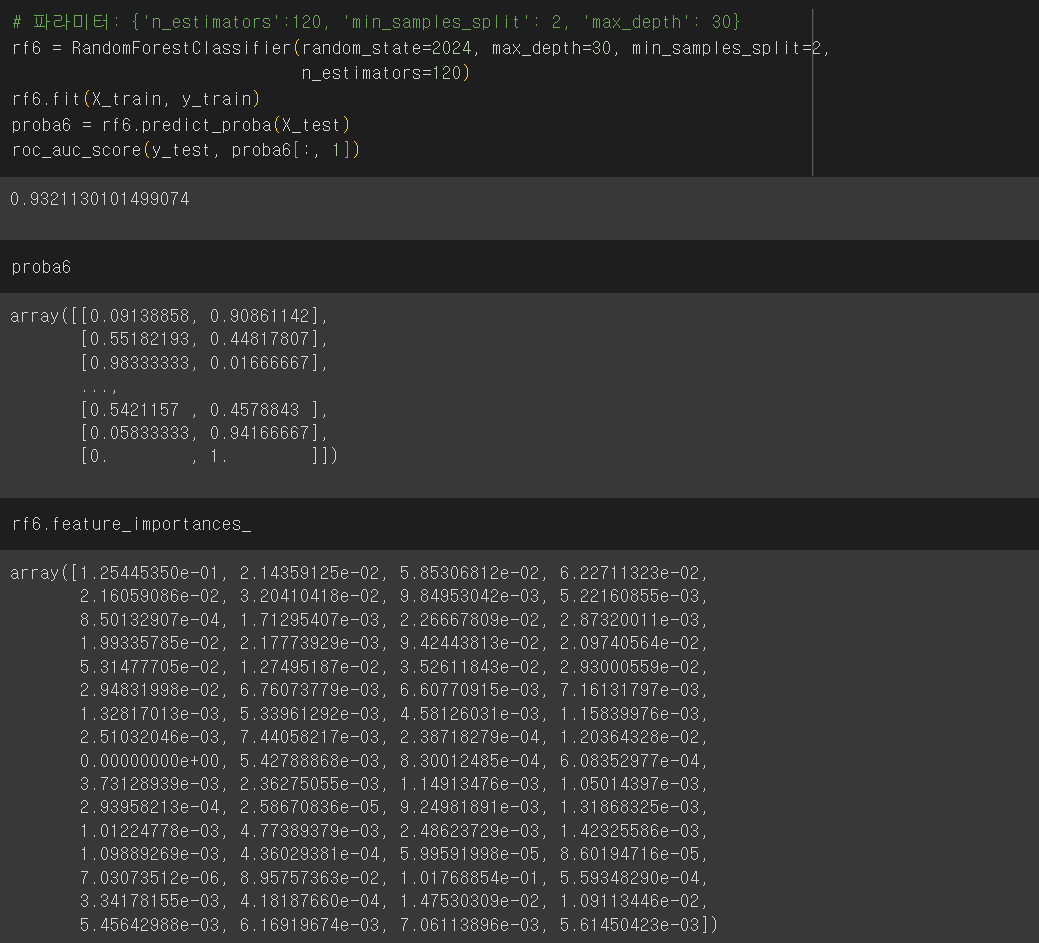
📌 'n_estimators=120' : 120개의 결정 트리를 사용하여 랜덤 포레스트를 구성한다.
5. 하이퍼 파라미터 최적의 값 찾기
- GridSearchCV: 원하는 모든 하이퍼 파라미터를 적용하여 최적의 값을 찾음
- RandomizedSearchCV: 원하는 하이퍼 파라미터를 지정하고 n_iter값을 설정하여 해당 수 만큼 random하게 조합하여 최적의 값을 찾음
✔️ GridSearchCV를 사용


📌 'rank_test_score': 테스트 점수의 순위

✔️ RandomizedSearchCV를 사용


6. 피처 중요도(Feature Importance)
- 결정 나무에서 노드를 분기할 때 해당 피처가 클래스를 나누는데 얼마나 영향을 미쳤는지 표기하는 척도
- 0에 가까우면 클래스를 구분하는데 해당 피처의 영향이 거의 없다는 뜻이며, 1에 가까우면 해당 피처가 클래스를 나누는데 영향을 많이 줬다는 의미




728x90
'데이터 분석' 카테고리의 다른 글
| 17. KMeans (1) | 2024.07.19 |
|---|---|
| 15. 서포트 벡터 머신 (0) | 2024.07.09 |
| 14. 로지스틱 회귀 (0) | 2024.07.09 |
| 13. 의사 결정 나무 (1) | 2024.07.09 |
| 12. 선형 회귀 (0) | 2024.07.09 |



