728x90
데이터: rent.csv
1. Rent 데이터셋


- Posted On: 매물 등록 날짜
- BHK: 베드, 홀, 키친의 개수
- Rent: 렌트비
- Size: 집 크기
- Floor: 총 층수 중 몇층
- Area Type: 공용공간을 포함하는지, 집의 면적만 포함하는지
- Area Locality: 지역
- City: 도시
- Furnishing Status: 풀옵션 여부
- Tenant Preferred: 선호하는 가족형태
- Bathroom: 화장실 개수
- Point of Contact: 연락할 곳



'BHK' 와 'Rent' 모두 독립변수 역할이 가능해보인다.




'rent_df['size']' 열에서 결측값을 해당 열의 중앙값(median)으로 채운다.
'rent_df' 의 모든 열에서 숫자형 데이터에 대해서만 중앙값을 계산하고 결측값을 해당 중앙값으로 채운다.


nunique() : 'Area Type' 열에서 고유한 값의 개수를 계산한다. 'Super Area', 'Carpet Area', 'Built Area' 세가지 고유한 값이 있어 결과는 3이다.
unique() : 고유한 값들을 반환한다.


✔️pd.get_dummies() : 주어진 DataFrame의 범주형(categorical) 변수들을 원-핫 인코딩(One-Hot Encoding)하여 새로운 더미(dummy) 변수들로 변환한다.
✔️pd.get_dummies() 함수 작동 방식:
- 주어진 'columns'에 포함된 각 열에 대해 범주형 변수를 원-핫 인코딩하여 새로운 더미 변수(열)들을 생성한다.
- 각 원본 열의 각 고유한 값은 새로운 더미 변수들의 이름으로 사용된다.
- 각 행은 원본 데이터에서 어떤 값이 있었는지에 따라 0 또는 1의 값을 가진다.
'Rent'값 예측하기

2. 선형 회귀(Linear Regression)
- 데이터를 통해 데이터를 가장 잘 설명할 수 있는 직선으로 데이터를 분석하는 방법
- 단순 선형 회귀분석(단일 독립변수를 이용)
- 다중 선형 회귀분석(다중 독립변수를 이용)

3. 평가 지표 만들기
3-1. MSE(Mean Squared Error)
- 예측값과 실제값의 차이에 대한 제곱에 대해 평균을 낸 값
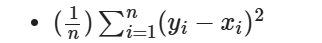

3-2. MAE(Mean Absolute Error)
- 예측값과 실제값의 차이에 대한 절대값에 대해 평균을 낸 값


3-3. RMSE(Root Mean Squared Error)
- 예측값과 실제값의 차이에 대한 제곱에 대해 평균을 낸 후 루트를 씌운 값



3-4. 평가 지표 적용하기

1837 인덱스 데이터가 이상치라 예상되므로 drop하고 다시 평가한다.

이상치인 1837 데이터를 삭제한 것이 오차가 줄었음을 알 수 있다.
728x90
'데이터 분석' 카테고리의 다른 글
| 14. 로지스틱 회귀 (0) | 2024.07.09 |
|---|---|
| 13. 의사 결정 나무 (1) | 2024.07.09 |
| 11. 아이리스 데이터셋 (0) | 2024.07.09 |
| 10. 사이킷런 (0) | 2024.07.09 |
| 9. 머신러닝 (0) | 2024.07.09 |



