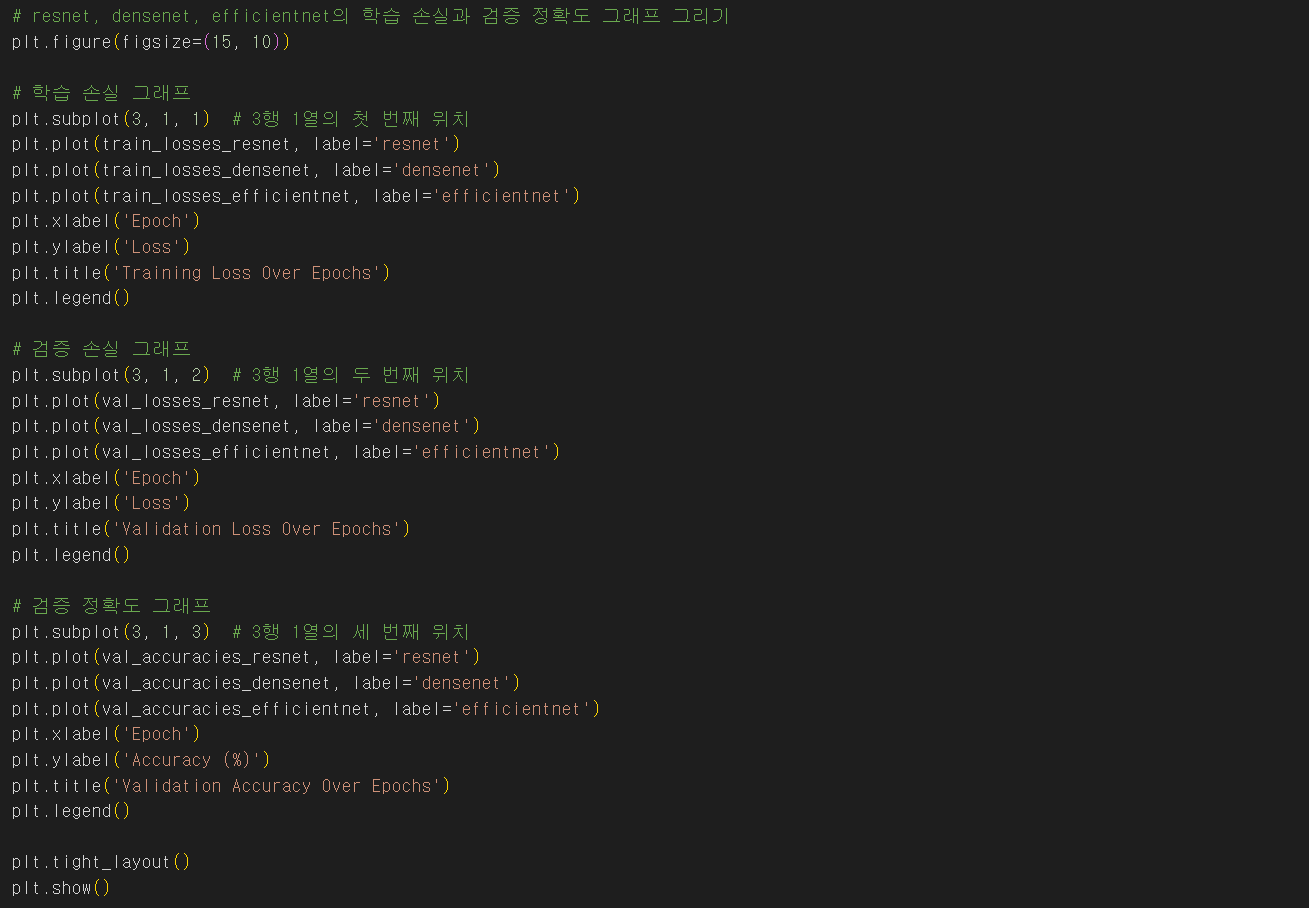
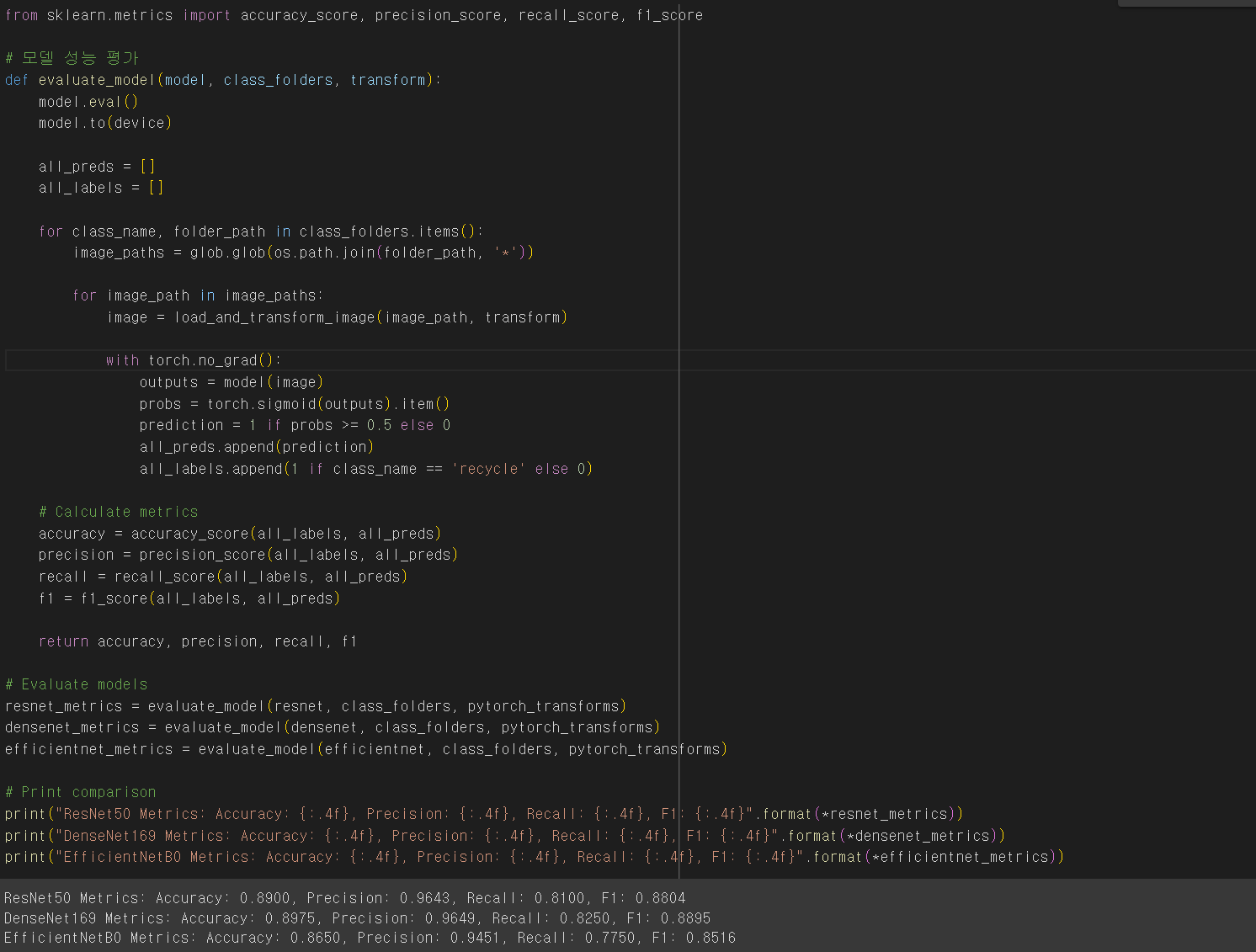
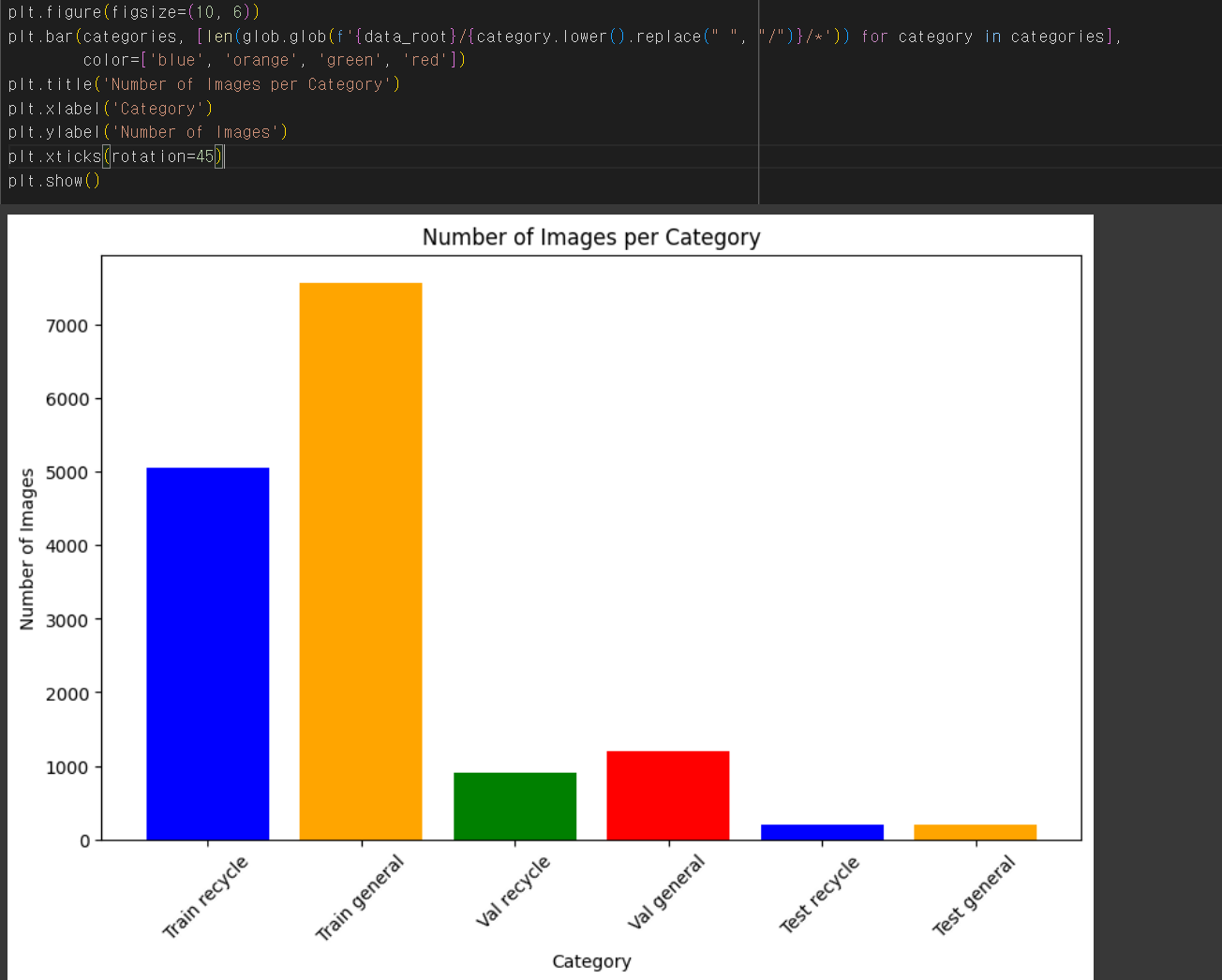
[컴퓨터 비전] ResNet, DenseNet, EfficientNet을 활용한 재활용품 이미지 분류하기








📌 resnet(Residual Network)
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
- ResNet은 딥러닝에서 이미지 분류, 객체 탐지 등의 작업에서 뛰어난 성능을 보이는 신경망 아키텍처이다. 이는 매우 깊은 신경망에서도 학습을 가능하게 한 혁신적인 모델로, 잔차 학습(residual learning)이라는 개념을 도입했다.
- Residual Learning:
- ResNet의 주요 아이디어는, 신경망이 직접 입력을 기반으로 출력을 학습하는 대신, 입력과 출력 사이의 차이(잔차, residual)를 학습하도록 하는 것이다.
- Residual Block(잔차 블록):
- 두 개의 3x3 합성곱 레이어
- ReLU 활성화 함수
- 입력 x를 그대로 출력에 더해주는 스킵 연결 -> 기울기 소실 문제를 해결
# resnet50 객체 생성
resnet = models.resnet50(pretrained=True)


📌 DenseNet(Densely Connected Convolutional Networks)
Densely Connected Convolutional Networks
Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observa
arxiv.org
- DenseNet은 딥러닝에서 이미지 분류, 객체 감지, 세분화와 같은 컴퓨터 비전 작업에 사용되는 신경망 아키텍처이다.
- Dense Block:
- 여러 개의 Dense Block으로 구성되어 있으며, 각 블록 내의 레이어는 서로 연결되어 있다. 이러한 연결은 입출력 간의 밀접한 관계를 형성하여 정보의 흐름을 원활하게 한다.
- Skip Connections:
- DenseNet의 각 레이어는 이전 레이어의 출력을 직접 연결하는 Skip Connection을 사용한다. 이 방식은 정보 손실을 줄이고, 기울기 소실 문제를 완화하여 네트워크가 더 깊어질 수 있도록 한다.
- 효율적인 파라미터 사용
- 각 레이어가 모두 이전 레이어의 출력을 사용하므로, 동일한 특성을 재사용할 수 있다. 이로 인해 상대적으로 적은 수의 파라미터로도 높은 성능을 달성할 수 있다.
- Growth Rate:
- 각 Dense Block 내의 레이어는 Growth Rate라는 하이퍼파라미터에 따라 결정된 수의 출력 피처 맵을 생성한다. 이 값은 Dense Block의 크기를 조절하는 데 중요한 역할을 한다.
📌 EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing n
arxiv.org
- 기존의 CNN 아키텍처에 비해 더 적은 계산 자원으로 높은 성능을 달성할 수 있도록 최적화되었다.
- Compound Scaling:
- 모델의 크기를 늘릴 때 Compound Scaling 기법을 사용하여 너비, 깊이 및 해상도를 동시에 조정한다. 기존의 모델에서 일반적으로 하나의 차원만 늘리는 것과 달리 세 가지 차원을 동시에 늘림으로써 성능과 효율성을 개선한다.
- MBConc Block:
- 이 블록은 Depthwise Separable Convolution을 활용하여 연산량을 줄이고, 더 적은 파라미터로도 성능을 유지할 수 있도록 한다. 또한 Squeeze-and-Excitation(SE) 모듈을 통합하여 채널 간의 관계를 학습하고, 중요한 피처를 강조한다.