딥러닝
3. 파이토치로 구현한 논리회귀
Uno_says
2024. 7. 25. 23:12
728x90
1. 단항 논리회귀(Logistic Regression)
- 이진 분류를 할 때 사용하며, 선형 회귀 공식으로부터 나왔기 때문에 논리회귀라는 이름이 붙여짐
- 회귀 분석을 기반으로 하지만 분류 문제에 사용
- 주로 시그모이드 함수를 사용


- 논리회귀는 입력 데이터 x에 대한 선형 결합 계산 -> 그 결과를 시그모이드 함수에 통과시켜 출력값을 0과 1사이의 값으로 변환 -> 이 값을 특정 클래스에 속할 확률로 계산



2. 비용함수
- Binary Cross Entropy
- 논리회귀에서는 nn.BCELoss() 함수를 사용하여 Loss 계산
- 1번 시그마, 2번 시그마 중에서 1번 시그마는 정답이 참이었을 때 부분, 2번 시그마는 정답이 거짓이었을 때 부분이다.
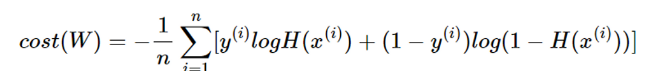


3. 다항 논리회귀

3-1. CrossEntropyLoss
- 교차 엔트로피 손실 함수는 Pytorch에서 제공하는 손실 함수 중 하나로 다중 클래스 분류 문제에서 사용
- 소프트맥스 함수와 교차 엔트로피 손실 함수를 결합한 형태
- 소프트맥스 함수를 적용하여 각 클래스에 대한 확률 분포를 얻음
- 각 클래스에 대한 로그 확률을 계산
- 실제 라벨과 예측 확률의 로그 값 간의 차이를 계산
- 계산된 차이의 평균을 계산하여 최종 손실 값을 얻음
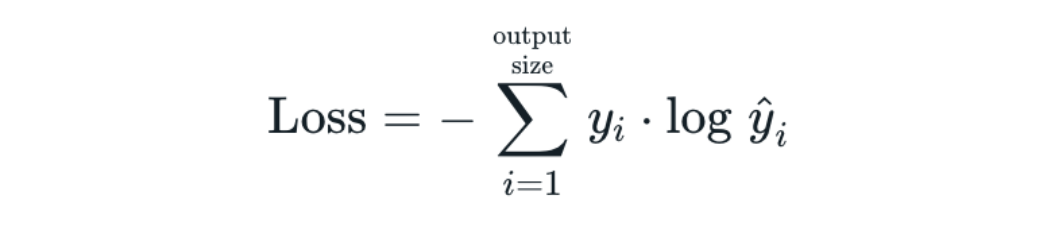
3-2. SoftMax
- 다중 클래스 분류 문제에서 사용되는 함수로 주어진 입력 벡터의 값을 확률 분포로 변환
- 각 클래스에 속할 확률을 계산할 수 있으며, 각 요소를 0과 1사이의 값으로 변환하여 이 값들의 합은 항상 1이 되도록 함
- 각 입력 값에 대해 지수함수를 적용
- 지수 함수를 적용한 모든 값의 합을 계산한 후, 각 지수의 합으로 나누어 정규화를 함
- 정규화를 통해 각 값은 0과 1사이의 확률 값으로 출력
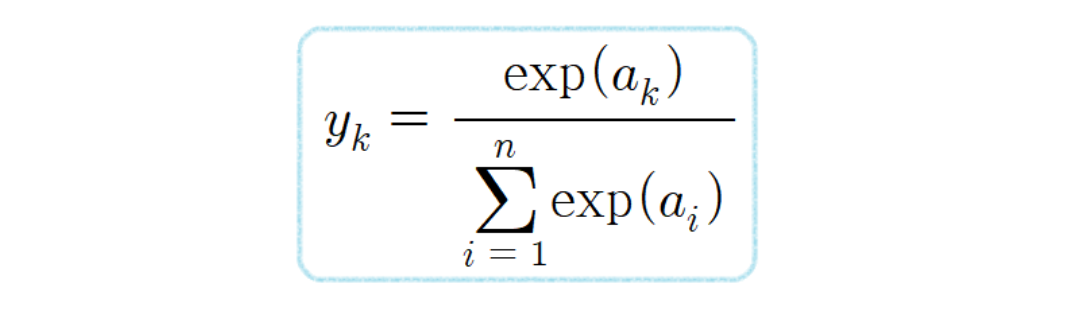


4. 경사 하강법의 종류
4-1. 배치 경사 하강법(Vanilla Gradient Descent)
- 가장 기본적인 경사 하강법
- 데이터셋 전체를 고려하여 손실함수를 계산
- 한 번의 Epoch에 모든 파라미터 업데이트를 단 한 번만 수행
- 파라미터 업데이트할 때 한 번의 전체 데이터셋을 고려하기 때문에 모델 학습 시 많은 시간과 메모리가 필요하다는 단점이 있음
4-2. 확률적 경사 하강법(Stochastic Gradient Descent)
- 확률적 경사 하강법은 배치 경사 하강법이 모델 학습 시 많은 시간과 메모리가 필요하다는 단점을 보완하기 위해 제안된 기법
- Batch Size를 1로 설정하여 파라미터를 업데이트 하기 때문에 배치 경사 하강법보다 훨씬 빠르고 적은 메모리로 학습을 진행
- 파라미터 값의 업데이트 폭이 불안정하기 때문에 정확도가 낮은 경우가 생길 수 있음
4-3. 미니 배치 경사 하강법(Mini-Batch Gradient Descent)
- 미니 배치 경사 하강법은 Batch Size를 설정한 size로 사용
- 배치 경사 하강법보다 모델 속도가 빠르고, 확률적 경사 하강법보다 안정적인 장점이 있음
- 딥러닝 분야에서 가장 많이 활용되는 경사 하강법
- 일반적으로 Batch Size를 4, 8, 16, 32, 64, 128과 같이 2의 n제곱에 해당하는 값으로 사용하는게 관례적
5. 경사 하강법의 여러가지 알고리즘
5-1. SGD(확률적 경사 하강법)
- 매개변수 값을 조정 시 전체 데이터가 아니라 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법
5-2. 모멘텀(Momentum)
- 경사 하강법의 단점을 보완하기 위해 도입된 알고리즘
- 관성이라는 물리학 법칙을 응용한 방법
- 접선의 기울기에 한 시점 이전의 접선의 기울기 값을 일정한 비율만큼 반영
- 이전 기울기의 이동 평균을 사용하여 현재 기울기를 업데이트
- 가속도를 제공하여, 경사 하강법보다 최솟값에 도달할 수 있음
5-3. 아다그라드(Adagrad)
- 모든 매개변수에 동일한 학습률(lr)을 적용하는 것은 비효율적이다라는 생각에서 만들어진 학습 방법
- 처음에는 크게 학습하다가 조금씩 작게 학습시킴
- 각 파라미터에 맞춤형 학습률을 적용하는 방법
- 희소한 데이터에서 유리함
- 시간이 지남에 따라 학습률이 계속 감소하여 학습을 멈출 수 있음
5-4. 아담(Adam)
- 모멘텀 + 아다그라드
- 각 매개변수에 대해 적응형 학습률을 적용하며, 과거의 기울기 정보를 활용해 현재의 학습률을 조절
- AdamW: Adam의 변형으로 L2정규화(가중치 감쇠)를 별도로 처리하여 더 나은 일반화 성능을 제공, L2 정규화가 학습률 조정과 섞여 불안정한 학습을 초래할 수 있는 문제를 해결
6. 와인 품종 예측하기
- sklearn.datasets.load_wine: 이탈리아의 같은 지역에서 재배된 세가지 다른 품종으로 만든 와인을 화학적으로 분석한 결과에 대한 데이터셋
- 13개의 성분을 분석하여 어떤 와인인지 구별하는 모델을 구축
- 데이터를 섞은 후 train 데이터를 80%, test 데이터를 20%로 하여 사용
- Adam을 사용

- 테스트 데이터의 0번 인덱스가 어떤 와인인지 알아보고 정확도를 출력해보자





728x90