데이터 분석
17. KMeans
Uno_says
2024. 7. 19. 14:52
728x90
1. Clusters(클러스터)
- 유사한 특성을 가진 개체들의 집합
- 고객분류, 유전자 분석, 이미지 분할

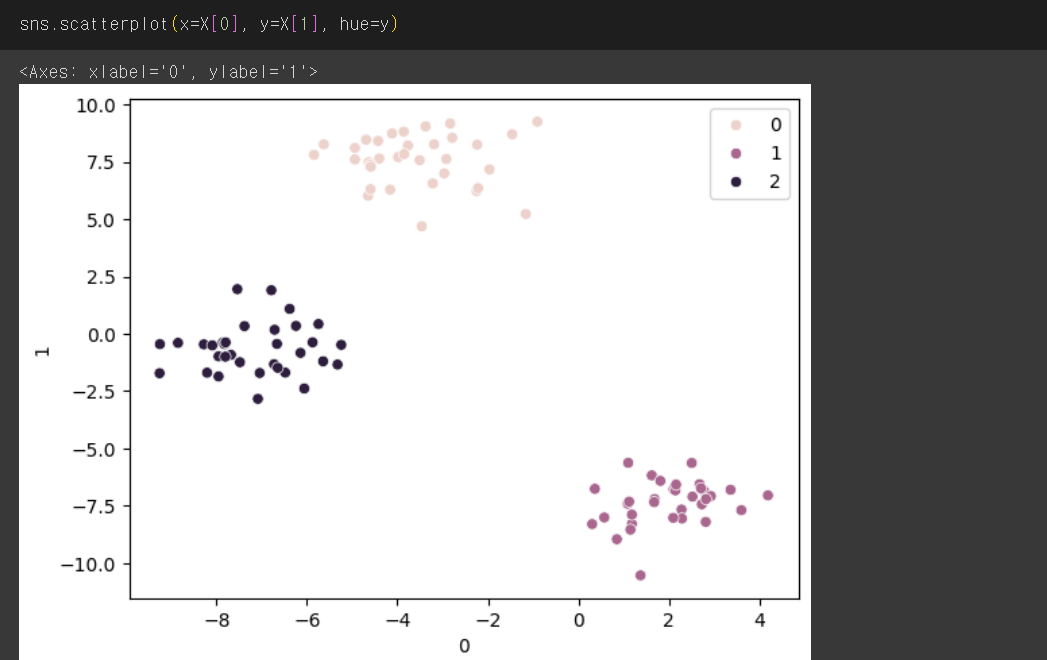
'x=X[0]' : 데이터셋의 첫 번째 특성(열)
'y=X[1]' : 데이터셋의 두 번째 특성(열)
'hue=y' : 각 데이터 포인트의 색상을 'y'에 따라 다르게 설정



2. marketing 데이터셋
데이터: marketing.csv















- fit(): 데이터의 평균과 표준편차를 계산한다.
- transform(): 데이터를 표준화(평균이 1, 표준편차가 1이 되도록)한다.

3. KMeans
- k개의 중심점을 찍은 후에 이 중심점에서 각 점간의 거리의 합이 가장 최소가 되는 중심점 k의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 알고리즘(k개의 클러스터의 수는 정해줘야 함)

- 군집의 개수(k) 설정 -> 초기 중심점 설정 -> [데이터를 군집에 할당(배정) -> 중심점 재설정(갱신)] 반복

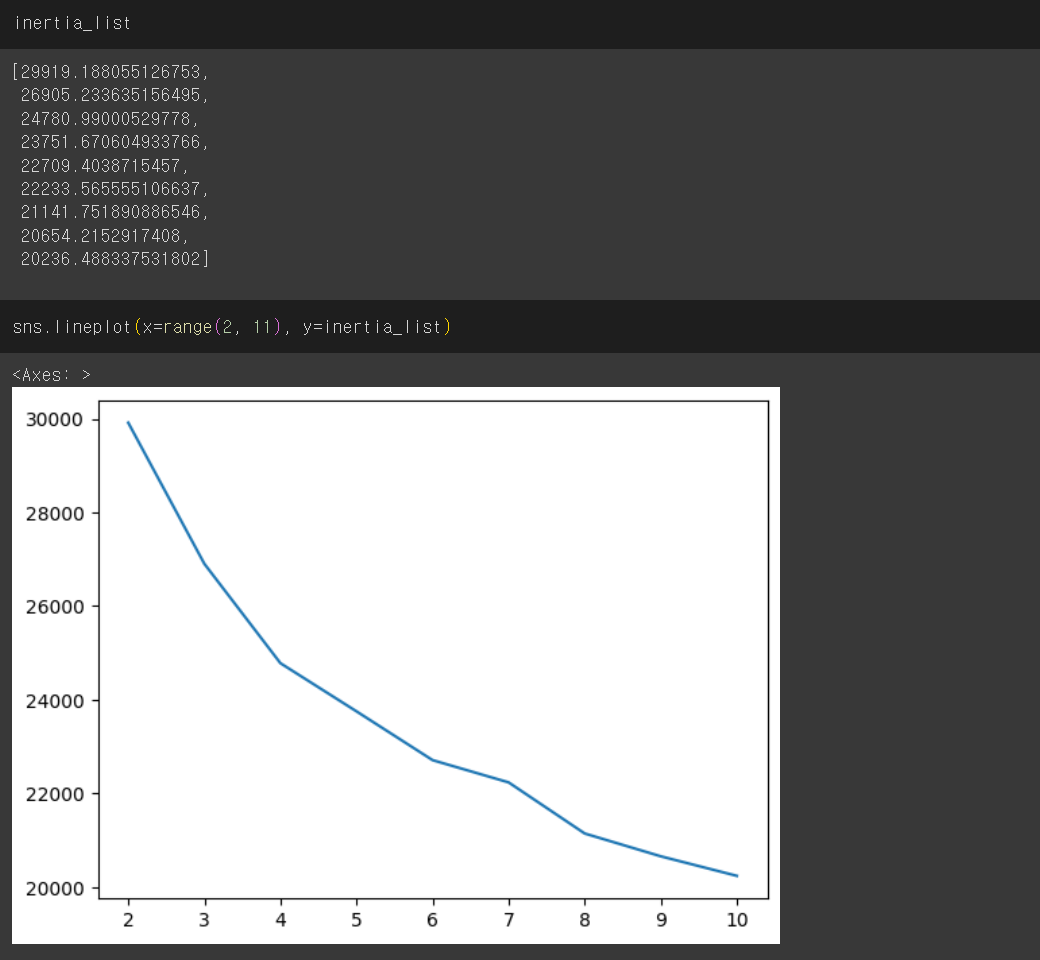
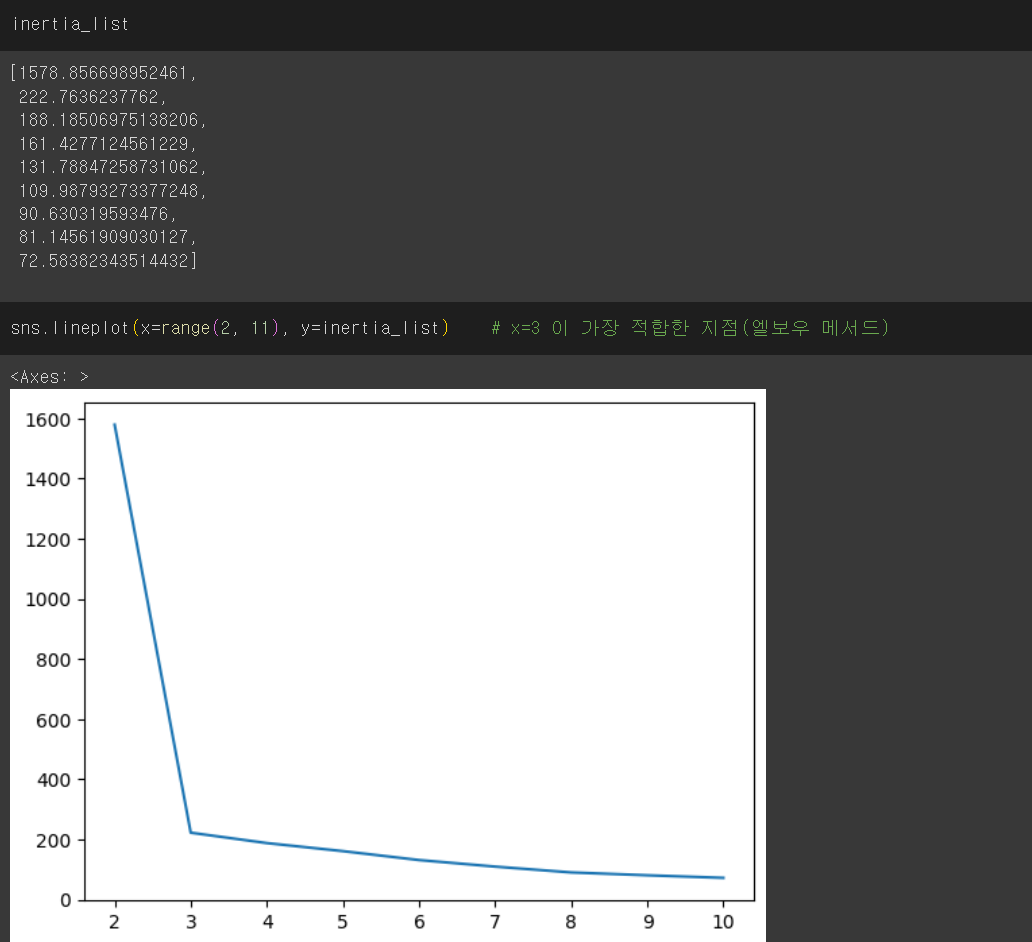
✔️ Inertia의 해석
- 낮은 inertia 값은 데이터 포인트가 클러스터 중심에 더 가깝다는 것을 의미하며, 이는 클러스터가 잘 정의되었음을 나타낸다.
- 높은 inertia 값은 데이터 포인트가 클러스터 중심에서 멀리 떨어져 있다는 것을 의미하며, 이는 클러스터가 잘 정의되지 않았음을 나타낼 수 있다.
4. 실루엣 스코어(Silhouette Score)
- 클러스터링의 품질을 평가하는 지표로, 각 데이터 포인트가 자신이 속한 클러스터와 얼마나 유사하고 다른 클러스터와는 얼마나 다른지를 측정
- -1에서 1사이의 값을 가지며, 값이 클수록 클러스터링의 품질이 높다고 볼 수 있음




728x90