데이터 분석
14. 로지스틱 회귀
Uno_says
2024. 7. 9. 22:01
728x90
데이터: hr.csv
1. hr 데이터셋


- employee_id: 임의의 직원 아이디
- department: 부서
- region: 지역
- education: 학력
- gender: 성별
- recruitment_channerl: 채용 방법
- no_of_trainings: 트레이닝 받은 횟수
- age: 나이
- previous_year_rating: 이전 년도 고과 점수
- length_of_service: 근속 년수
- awards_won: 수상 경력
- avg_training_score: 평균 고과 점수
- is_promoted: 승진 여부








📌결측치 확인

📌결측치 제거(axis=0 : 행 제거)
결측치가 있는 행들을 제거한다. (54808개의 행 -> 48660개의 행)

📌get_dummies()

필요없는 열 제거

📌학습
'is_promoted' 예측하기

2. 로지스틱 회귀(Logistic Regression)
- 둘 중의 하나를 결정하는 문제(이진 분류)를 풀기 위한 대표적인 알고리즘
- 다항 분류 문제에도 확장될 수 있음
- 종속 변수 Y는 두 가지 범주 중 하나를 가짐(예: 0 또는 1)
- 특정 범주의 속할 확률을 예측하는 것

▶ 로지스틱 회귀 모델은 일반화 선형 모델의 일종으로, 독립 변수의 선형 조합을 로지스틱 함수(시그모이드 함수)를 사용하여 종속 변수에 대한 확률 점수로 변환

3. 혼돈 행렬(confusion matrix)
- 분류 문제에서 정밀도와 재현율(민감도)을 활용하는 평가용 지수


- True Positive (TP): 실제로 양성(True Positive)이고, 모델이 양성으로 예측한 경우
- True Negative (TN): 실제로 음성(True Negative)이고, 모델이 음성으로 예측한 경우
- False Positive (FP): 실제로 음성(False Positive)인데, 모델이 양성으로 예측한 경우 (Type ⅠError)
- False Negative (FN): 실제로 양성(False Negative)인데, 모델이 음성으로 예측한 경우 (Type Ⅱ Error)
| 예측: 양성 (Positive) |
예측: 음성 (Negative) |
|
| 실제: 양성 (Positive) | TP | FN |
| 실제: 음성 (Negative) | FP | TN |
3-1. 정밀도(Precision)
- TP / (TP + FP)
- 무조건 양성으로 예측해서 계산하는 방법
- 양성으로 예측한 것들 중에서 실제로 양성인 비율
3-2. 재현율(Recall)
- TP / (TP + FN)
- 정확하게 감지한 양성 샘플의 비율
- 실제로 양성인 것들 중에서 양성으로 예측한 비율
- 민감도(Sensitivity) 또는 TPR(True Positive Rate)라고도 부름
3-3. f1 score
- 정밀도와 재현율의 조화평균을 나타내는 지표



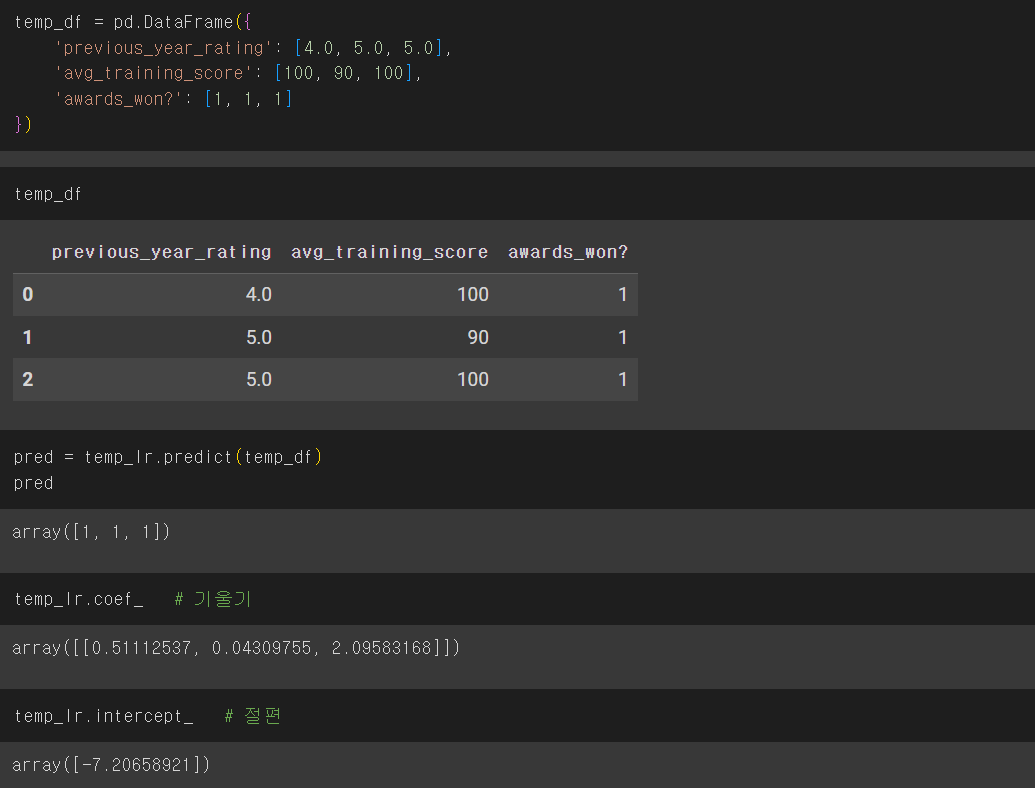
📌'hr_df'로 학습시키기

📌새로운 데이터('temp_df')로 테스트

4. 교차 검증(Cross Validation)
- train_test_split 에서 발생하는 데이터의 섞임에 따라 성능이 좌우되는 문제를 해결하기 위한 방법
- k겹(k-Fold) 교차 검증을 가장 많이 사용

📌'n_splits=5' 이므로 train_index와 test_index의 비는 4:1 이다.
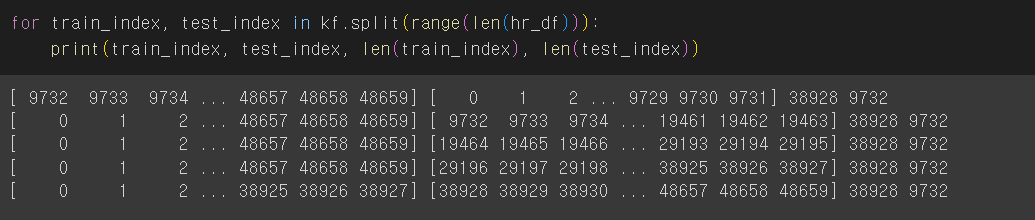
📌'shuffle=True' 를 함으로써 데이터를 섞어준다.

📌KFold 교차 검증을 사용하여 로지스틱 회귀 모델의 성능 평가

📌'n_splits=5' 이므로 5번의 교차검증을 한 accuracy값들이 나온다.

✔️교차검증을 사용하는 이유는 결과를 좋게 함이 아니라, 믿을만한 검증을 하기 위함이다.
728x90